8 min read
Best practices for infrastructure, data, and development.
In today's AI-driven landscape, your business's competitive edge lies in how effectively you integrate AI into your product and workflows.
This guide focuses on three critical aspects of building scalable AI applications:
Choosing and implementing AI models as they release
Managing and preparing your unique data for AI
Developing and optimizing future-proof infrastructure
Choosing the right provider
Choosing AI providers, such as OpenAI, Anthropic, and Google—or even fine-tuning or rolling your own model—can be daunting.
While each has pros and cons, the Vercel AI SDK offers the flexibility to work with multiple providers, allowing you to take advantage of each of their best features without being locked into a single ecosystem.
Full model portability like this enables you to:
Easily switch providers to optimize for different strengths (speed vs. world knowledge vs. coding expertise, etc.)
Experiment quickly and concretely with different models using environment variables or feature flags
Match model capability and price to task
Future-proof your application, so it can always be powered by the top-performing models and evolutions in the AI landscape
Building for the future of AI
Architecting for multi-modality and the next evolution in AI—generative UI—is crucial for future-proofing your applications.
With recent updates to the AI SDK, developers can now stream UI components directly from AI models, enabling dynamic, AI-generated user interfaces. This allows for real-time, context-aware UI generation.
The SDK also supports multi-modal AI, which allows for sophisticated AI applications that can process and generate diverse content types. This enables you to create features like image analysis, audio transcription, text-to-speech capabilities, and much more.
With Vercel and the AI SDK, you can worry less about making the right choice and instead spin up entire AI proofs-of-concept in just a few hours. At Vercel, for instance, we use feature flags and the AI SDK to quickly evaluate various providers for generating UI in v0.
Integrating any model into your app with the AI SDK is just a few lines of code:
import { generateText } from "ai";import { anthropic } from "@ai-sdk/anthropic";
const { text } = await generateText({ model: anthropic("claude-3-5-sonnet-20240620"), prompt: "What is the best way to architect an AI application?",});Third-party, fine-tuning, or in-house models
Depending on your use case, you may use pre-trained models, fine-tune existing models, or develop custom models in-house.
Pre-trained models: Today's LLMs are extremely capable out of the box, with offerings that keep your data completely secure. Thoroughly test existing options before opting for additional complexity.
Fine-tuning: Most major providers offer straightforward paths to fine-tune models for specialized tasks or training on your business's data.
Custom model: Introduces extreme complexity but is sometimes required for very unique workloads (competitive advantage) or instances where data privacy is paramount (banking, healthcare, etc.).
Whichever route you go, you can still use all the conveniences of the AI SDK.
Data cleansing and management
Well-prepared data is fundamental to the success of any AI initiative. Whether you're fine-tuning models or leveraging out-of-the-box LLMs with Retrieval-Augmented Generation (RAG), ensuring high-quality, domain-specific data is crucial.
When implementing AI, consider these key aspects of data management:
Data cleaning and normalization: Remove inconsistencies, errors, and outliers from your dataset while standardizing formats to ensure uniformity across all data points.
Handling missing or inconsistent data: Develop strategies to address gaps in your data, such as filling in missing values with educated estimates or creating clear rules for dealing with incomplete records, to maintain the integrity and usefulness of your dataset.
Ensuring data diversity and representativeness: To prevent biases and improve model generalization, strive for a dataset that accurately reflects the variety and distribution of real-world scenarios your AI will encounter. Monitor performance carefully to avoid overfitting.
Managing large datasets efficiently: Implement scalable data storage and processing solutions, such as distributed computing or cloud-based services, to handle large data without compromising performance or accessibility.
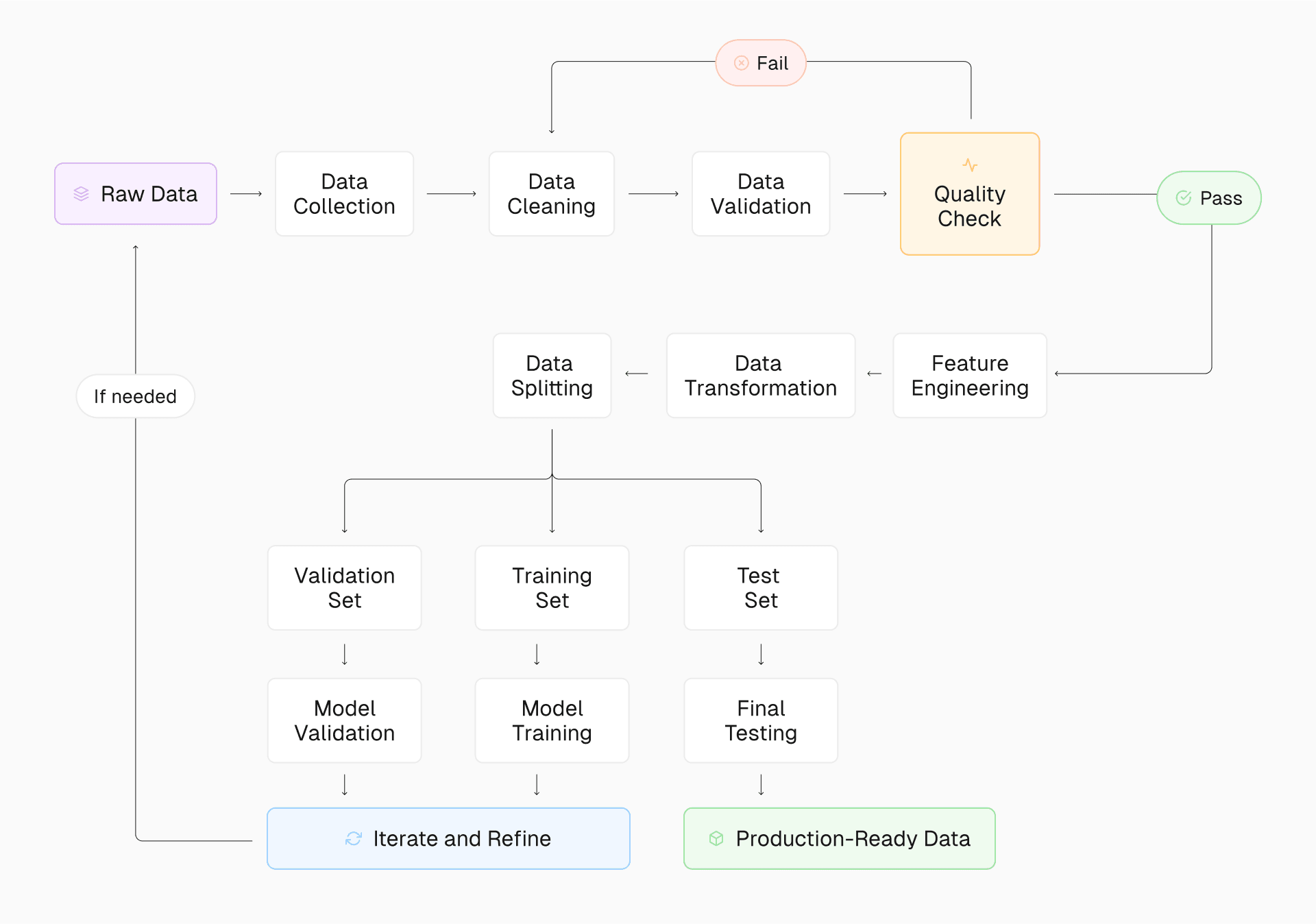
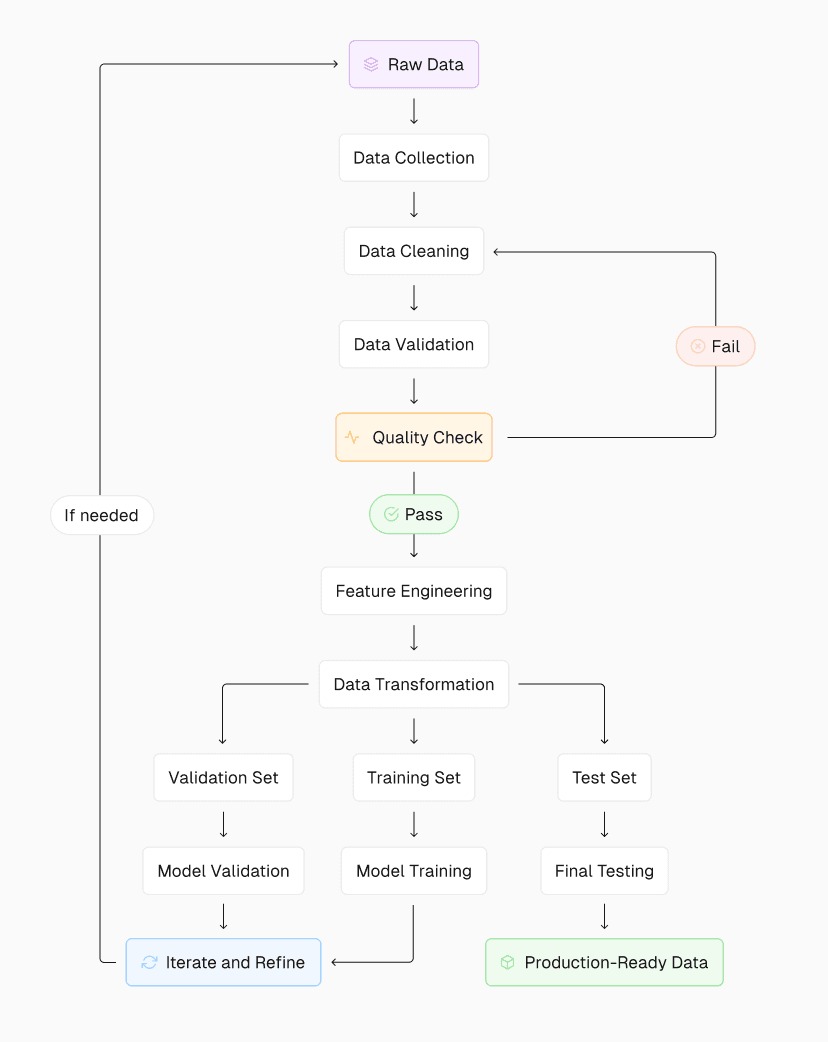
Retrieval-augmented generation (RAG) techniques
For many applications, RAG offers a powerful alternative to fine-tuning. RAG allows you to enhance out-of-the-box LLM outputs with your specific data, improving accuracy and relevance without the complexity of model training.
While basic RAG implementations are powerful, there are several advanced techniques to consider:
Multi-modal RAG: Expand your knowledge base beyond text to include images, audio, and video. For example, you could use image embeddings to retrieve relevant visuals alongside text, enhancing the context provided to the LLM.
Dynamic RAG: Update your knowledge base in real time, ensuring the model can always access the most current information. This can be achieved by implementing a system that continuously ingests new data and updates the vector store, as demonstrated in the Vercel AI SDK guide.
Personalized RAG: Tailor the retrieval process to individual users based on their preferences or context. This could involve maintaining user-specific vector stores or applying user-based filters to the retrieval results.
Explainable RAG: Enhance the system's ability to provide clear explanations and cite specific sources, improving transparency and trust. This can be implemented by including metadata with each chunk and instructing the LLM to reference these sources in its responses.
These advanced techniques can significantly improve the capabilities of your AI application, allowing for more versatile, up-to-date, and user-centric responses.
Simplified implementation with Vercel
Vercel's platform simplifies the implementation of RAG and other data-intensive AI workflows, enabling developers to create intuitive interfaces that set applications apart. This frontend-focused approach ensures that AI is seamlessly integrated into a superior user experience.
The AI SDK, with Next.js' powerful data fetching patterns and Vercel's Secure Compute, streamlines connecting various data sources and APIs to inform LLM answers. This approach allows you to leverage existing models while incorporating your proprietary data, offering a more straightforward path to enterprise-grade AI applications.
Keep in mind that AI—especially agentic workflows—can help you automate this whole process. Implementing data preparation workflows on Vercel can be a great way to get your feet wet deploying low-risk AI workloads.
The quickest way to build and secure AI features.
There’s no need to wait for your current platform to catch up. Build intelligent, user-centric applications that deliver exceptional experiences.
Get Started
Choosing the right infrastructure
Selecting the best infrastructure for your AI application means ensuring performance, scalability, cost-effectiveness, and reliability.
When choosing your infrastructure, consider these factors:
Latency: Users expect quick responses, even from AI-powered features.
Caching: Efficient caching reduces latency and minimizes redundant AI computations.
Streaming capability: Stream AI responses for real-time interaction.
Long-running processes: Some AI tasks may exceed typical serverless time limits.
Scalability: Your infrastructure should handle variable workloads and traffic spikes.
Memory and compute: AI models can be resource-intensive and require robust hardware.
Developer experience: Choose a platform that prioritizes developer productivity.
Frontend framework support: Compatibility with modern frontend frameworks for building responsive, future-proof user interfaces powered by AI.
Data storage and retrieval: Efficient handling of large datasets is crucial for AI performance.
Integration: Ensure compatibility with your existing tech stack and AI providers.
Cost: Balance per-token pricing, infrastructure costs, and development resources against potential ROI. If you create your own model or extensively fine-tune, factor in costs for GPUs and cross-functional labor.
You can solve these challenges with cloud providers like AWS, Google Cloud, and Azure, but you'll spend quite a bit of time setting up and maintaining complex configurations.
Vercel provides an AI-native experience out of the box, reducing ongoing operational costs and ensuring that any single frontend developer can innovate at the moment of inspiration.
Edge Network: Vercel's Edge Network serves billions of requests globally, using next-gen technology to deliver dynamic AI workloads at the speed of the static web.
Streaming serverless functions: Vercel Functions support streaming responses and long-running tasks, ideal for real-time interaction and incremental LLM responses.
Scalable compute: Vercel's serverless infrastructure means that even the spikiest workloads are perfectly balanced—with zero configuration needed. 99.99% uptime guaranteed.
Powerful, automated frontends: Vercel and the AI SDK support 35+ frontend frameworks, using framework-defined infrastructure to ensure developers don't need to write a single line of configuration code.
Data integration: Vercel's serverless-enabled storage options and seamless integrations with third-party providers mean that you always have access to the best data shape for the job at hand.
For any piece of the puzzle not solvable on Vercel—namely, training and hosting a custom model—keep in mind that you can seamlessly and securely connect Vercel's Frontend Cloud to your custom backend infrastructure with Secure Compute.
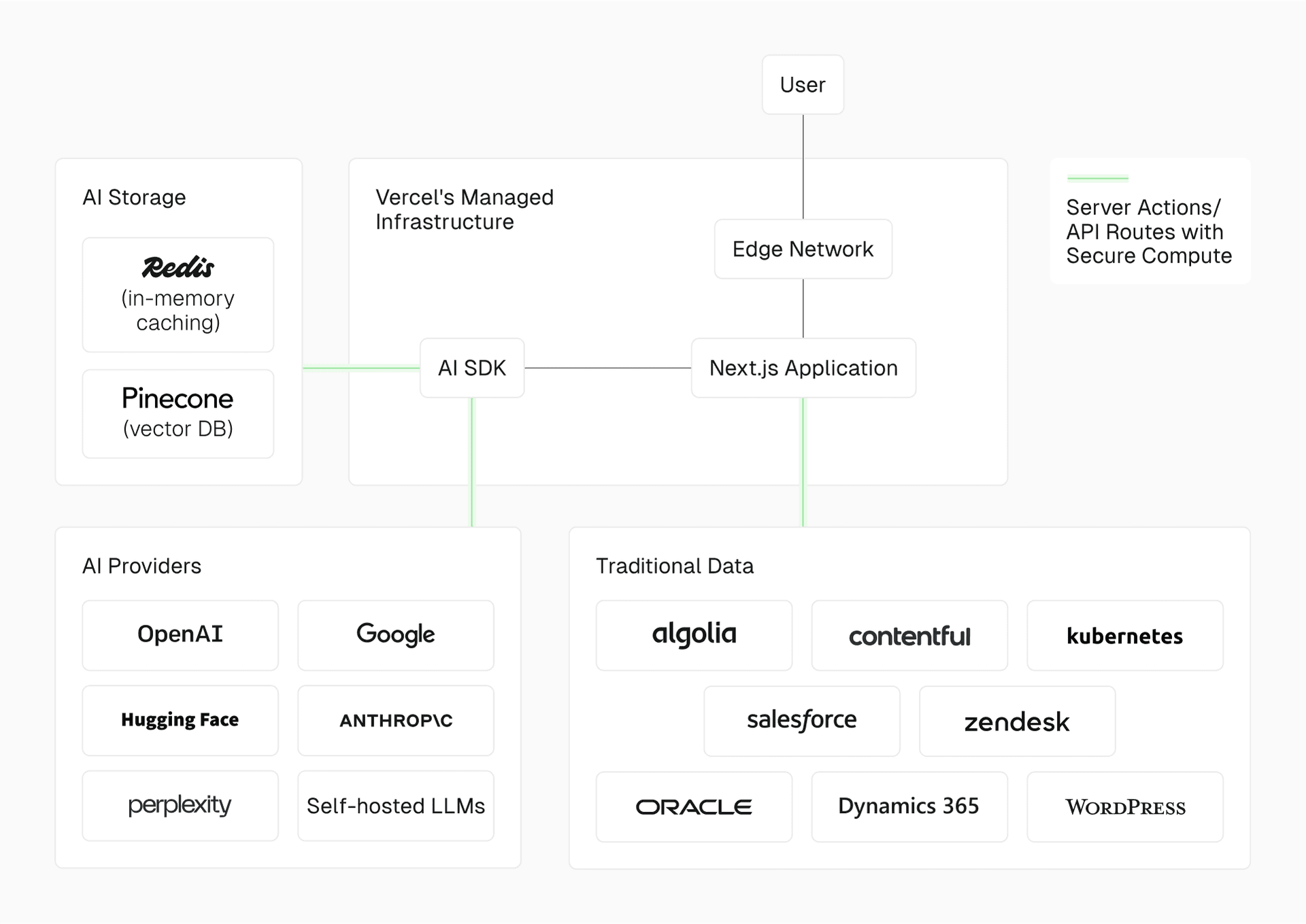
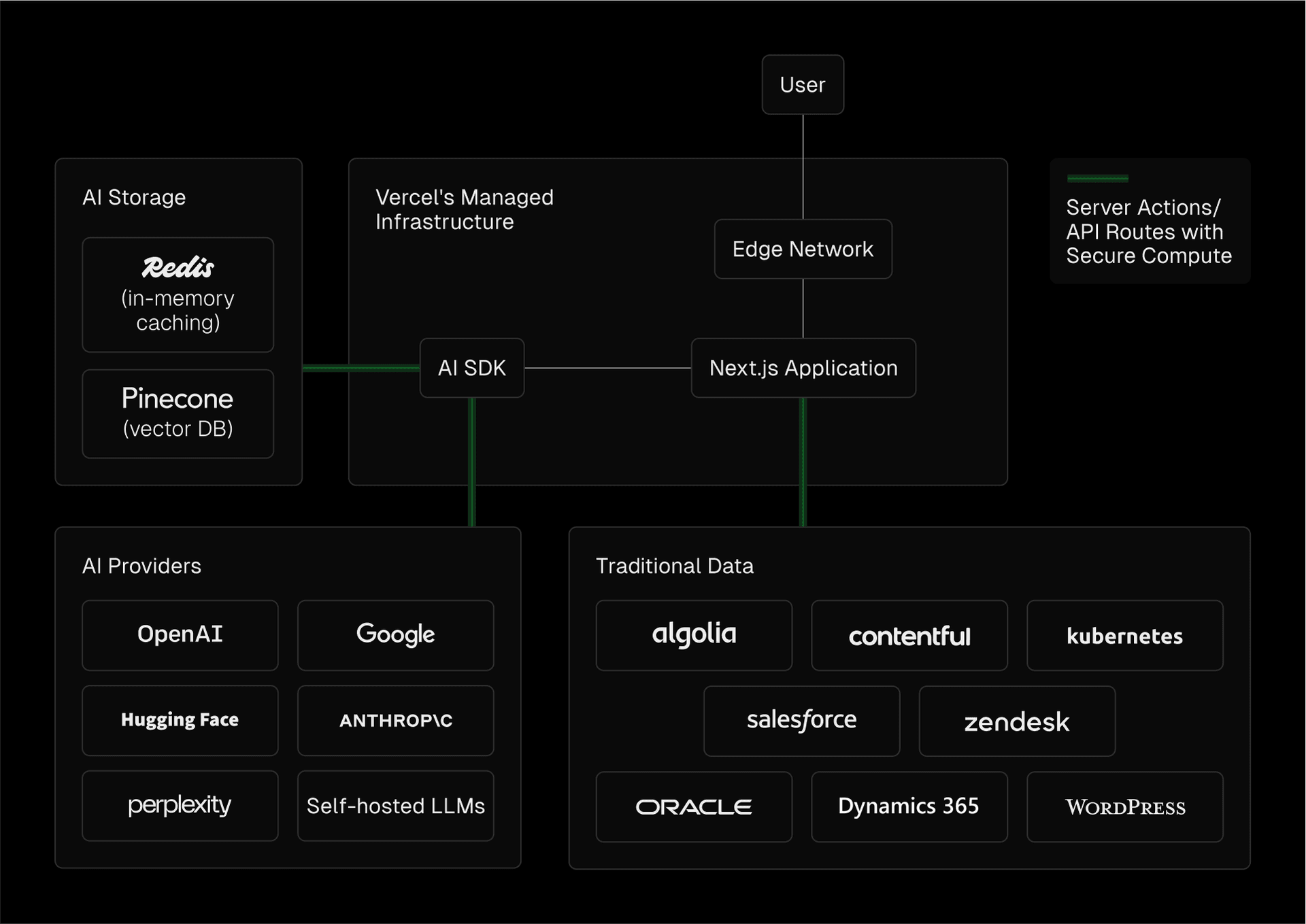
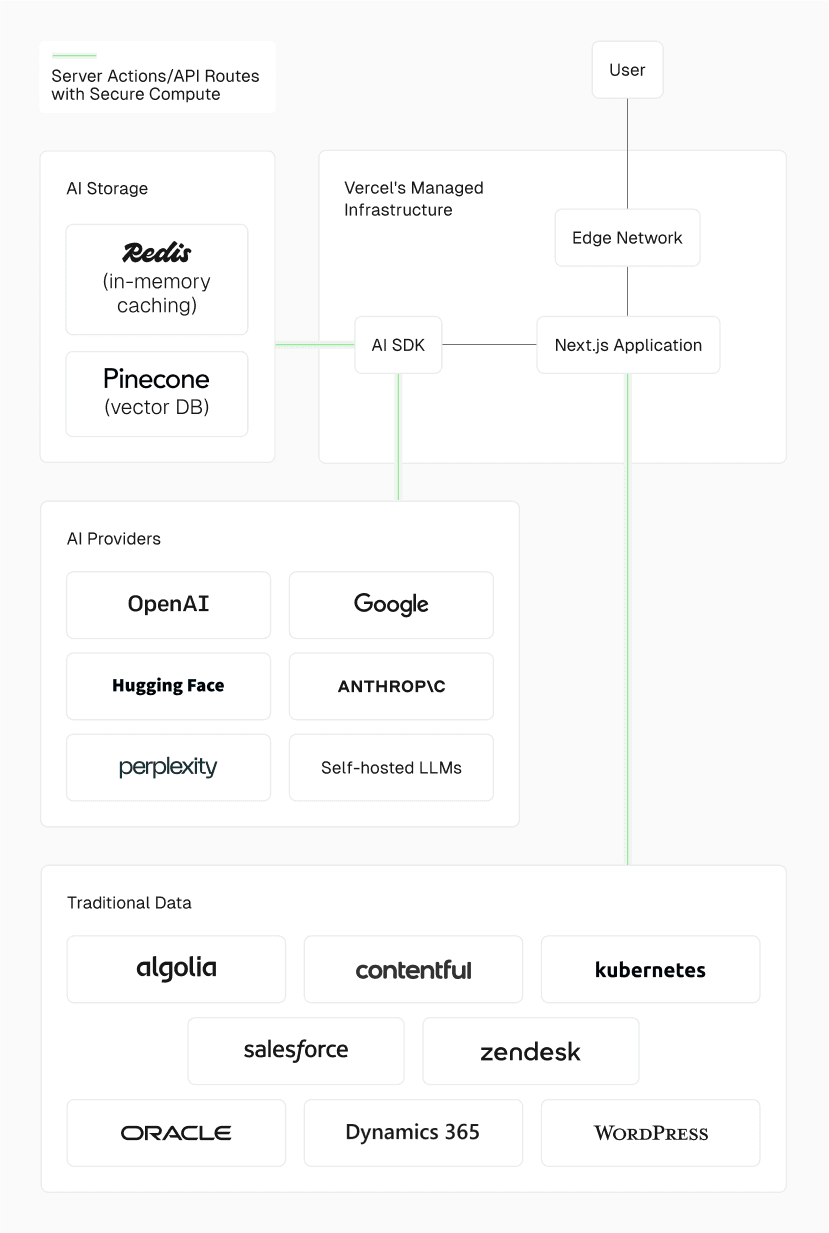
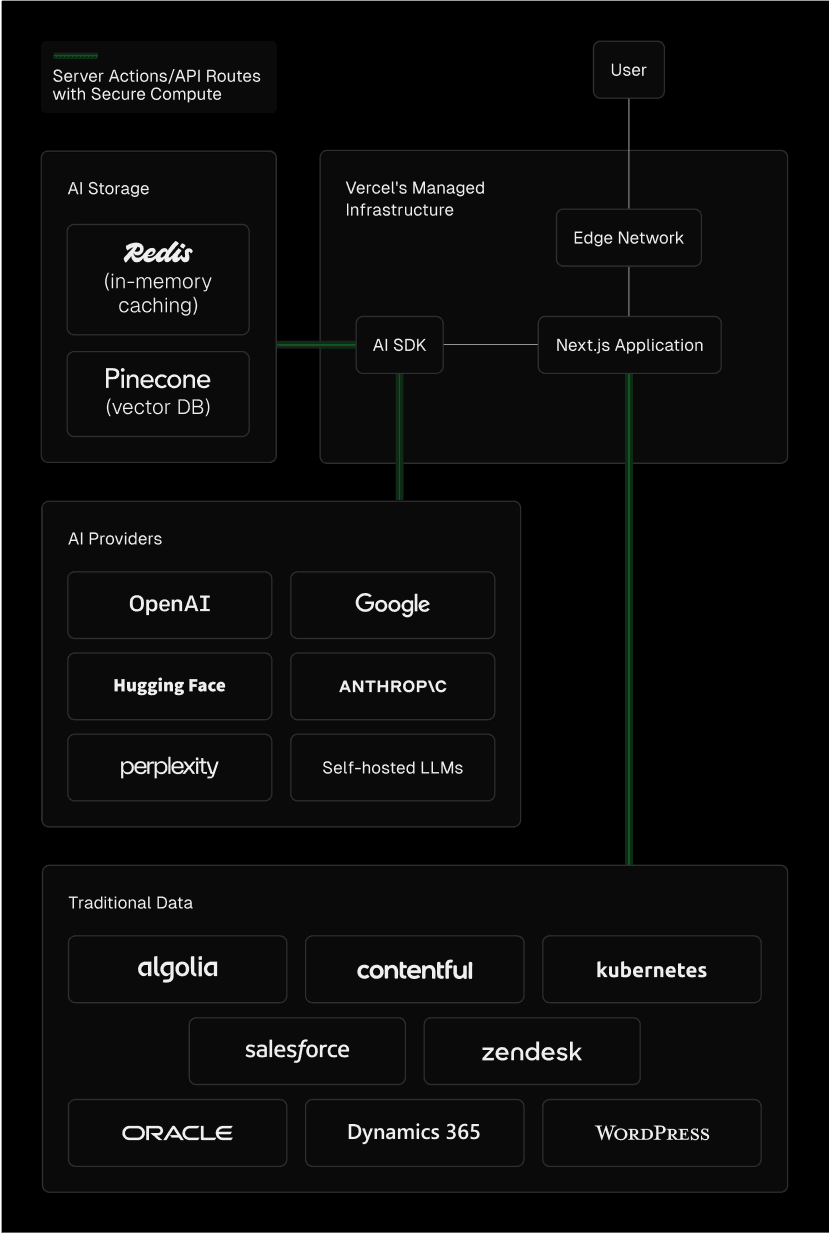
Optimizing AI application performance
While choosing the right infrastructure is crucial, optimizing your AI application's performance is equally important for delivering a smooth user experience and managing costs effectively. Here are some key strategies to consider.
Streaming
Streaming has become a cornerstone of AI apps, allowing for real-time data processing and immediate display of results, which drastically improves the responsiveness of your application.
The Vercel AI SDK provides a powerful streaming toolkit for all supported frameworks and models. Here's a simple example of how to implement streaming:
import { openai } from "@ai-sdk/openai";import { convertToCoreMessages, streamText } from "ai";
// Allow streaming responses up to 30 secondsexport const maxDuration = 30;
export async function POST(req: Request) { // Extract the `messages` from the body of the request const { messages } = await req.json();
// Call the language model const result = await streamText({ model: openai("gpt-4o"), messages: convertToCoreMessages(messages), });
// Respond with the stream return result.toDataStreamResponse();}This setup lets you stream AI-generated responses directly to your frontend, providing a more engaging and responsive user experience.
To further optimize streaming performance, consider the following techniques:
Chunking: Break down large datasets into smaller, manageable pieces. This allows for faster processing and reduces memory usage.
Backpressure handling: Implement mechanisms to manage the flow of data between the AI model and the client. This ensures your application remains responsive and doesn't consume unnecessary resources.
Multiple streamables: For complex UI components, consider breaking up streams into multiple, independently updatable parts. This allows for more granular updates and can further improve the responsiveness of your application.
By implementing these streaming optimizations, you can significantly enhance the performance and efficiency of your AI applications on Vercel's platform. Remember to profile and test your optimizations to ensure they provide tangible benefits for your specific use case.
Caching
Implement caching to store and reuse common AI responses. Vercel offers multiple caching options that can be leveraged to optimize your AI application's performance:
Incremental Static Regeneration (ISR): For AI-generated content that doesn't need real-time updates, ISR can be an excellent choice. It works with the Data Cache, a specialized cache on Vercel's global edge network for storing responses from data fetches that supports time-based, on-demand, and tag-based revalidation.
Strategic use of ISR reduces the load on your AI and backend services.
Redis / Vercel KV: Use Vercel KV, a fully managed Redis database, for storing and retrieving JSON data. It's ideal for caching AI responses, managing application state, and storing frequently accessed data. You can also integrate a self-managed Redis instance for more customized caching needs.
Blob Storage / Amazon S3: While not strictly a caching solution, blob storage is useful for AI applications that store and serve large files generated or processed by AI models.
Vercel Blob (Beta) is a managed blob storage configurable directly from the Vercel dashboard.
Here's an example of implementing caching for an AI response using Vercel KV and Next.js:
import { openai } from "@ai-sdk/openai";import { convertToCoreMessages, formatStreamPart, streamText } from "ai";import kv from "@vercel/kv";
// Allow streaming responses up to 30 secondsexport const maxDuration = 30;
// simple cache implementation, use Vercel KV or a similar service for productionconst cache = new Map<string, string>();
export async function POST(req: Request) { const { messages } = await req.json();
// come up with a key based on the request: const key = JSON.stringify(messages);
// Check if we have a cached response const cached = await kv.get(key); if (cached != null) { return new Response(formatStreamPart("text", cached), { status: 200, headers: { "Content-Type": "text/plain" }, }); }
// Call the language model: const result = await streamText({ model: openai("gpt-4o"), messages: convertToCoreMessages(messages), async onFinish({ text }) { // Cache the response text: await kv.set(key, text); await kv.expire(key, 60 * 60); }, });
// Respond with the stream return result.toDataStreamResponse();}What will your AI journey look like?
As AI reshapes technology, architects must look to robust infrastructure to harness its power without giving up security, compliance, and user trust.
Vercel's platform offers AI-native tooling that simplifies deployment and addresses critical concerns. With its global edge network, serverless infrastructure, and built-in security features, Vercel provides a foundation for innovative, scalable, and trustworthy AI applications.
You can create AI solutions that drive business value while maintaining trust, and position your organization at the forefront of the AI revolution.
Bring any questions.
Our AI engineers can answer your migration or complex infrastructure questions and recommend best practices for your AI app at scale.
Contact Us